



以 40K 高下文,让 Agent 搜索 2048 轮,性能还能一谈涨?这险些是不可想象的。
刻下主流的 Search Agent 都濒临归并个难熬:Agent 需要反复搜索网页、比对痕迹、考证假定、回溯修正,交互轮次动辄数十上百轮。但以 ReAct 为代表的传统范式,把每一轮的念念考和器用复返抵制持续追加到归并个高下文窗口中 —— 作念得越多,高下文越肥壮,留给推理的空间越少,早期的噪声和无理旅途还被永远「焊死」在追想里。
抵制即是:Agent 搜得越深切,反而「想」得越费解。
能不行让 Agent 在探索经过中持续「清算责任台」,历久在一个干净的空间里念念考?
来自中国东谈主民大学与阿里巴巴通义实验室的贪图团队提议了 IterResearch,一种全新的迭代式深度贪图范式。
{jz:field.toptypename/}通过马尔可夫式的责任空间重构,IterResearch 让 Agent 在仅 40K 高下文长度下完成了 2048 次器用交互且性能不衰减,在 BrowseComp 上从 3.5% 一谈攀升至 42.5%。
当今,该论文已被 ICLR 2026 接管。

「堆高下文」为什么难以闭幕 Interaction Scaling?
在 Search Agent 场景下,Agent 的责任试验上是一个与外部环境约束交互的轮回。传统 ReAct 范式将这仍是过建模为「单高下文堆叠」:每一轮的推理和器用复返被捏续追加到归并个高下文窗口中,变成线性增长的追想链。
这种看似当然的遐想,在长程任务中会激勉两个结构性问题:
其一是高下文窒息(context suffocation):高下文窗口的总容量是有限的,历史信息持续堆积意味着留给后续推理的「生成预算」被捏续压缩。Agent 被动给出更短、更浅的回答,最终滑向猖獗的论断;
其二是噪声混浊(noise contamination):搜索经过中产生的多量网页节录、早期的无理旅途和无关痕迹被永远写入高下文,对后续推理产生级联干豫,信噪比捏续走低。
社区已经领路到了这些问题,连续提议了 context folding、summary 等缓解计谋,试图为摇摇欲坠的高下文「续命」。但这些步伐试验上是在挽救,并未从根底上改变高下文线性增长的结构 —— 给 Agent 256K 致使更长的窗口,也仅仅推迟崩溃,而非幸免崩溃。
不再「堆叠」,而是「重构」:IterResearch 的中枢念念路
IterResearch 对这一问题的复兴不是修修补补,而是从范式层面再行念念考:与其持续往高下文里塞东西,不如让 Agent 学会「边作念边清算」。
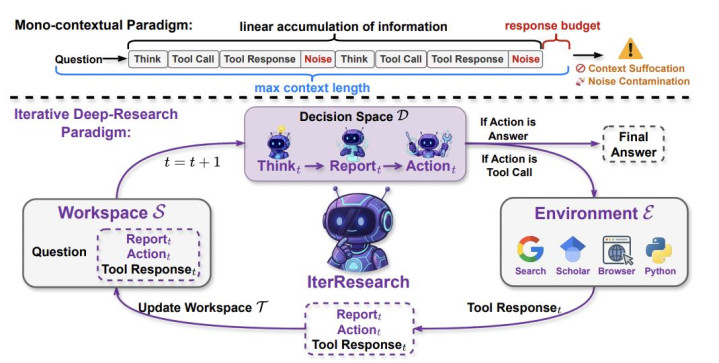
贪图团队将长程贪图经过体式化为一个马尔可夫有筹画经过(MDP)。中枢念念想是:Agent 不再爱戴一个持续扩张的齐全历史,而是通过一个捏续进化的「演进式敷陈」(evolving report)来轮廓已有抵制、压缩无关信息、更新推理景况。每一轮推理都在一个被重构过的、恒定复杂度的责任空间中张开。
具体来说,Agent 的每一步包含两个中枢动作:
有筹画阶段:Agent 基于刻下景况,输出三部分 —— 念念考经过(Think)、更新后的演进敷陈(Report)和本轮器用调用申请(Action)。敷陈在这里饰演了「压缩追想」的脚色,Agent 需要在每一轮主动决定哪些信息值得保留,哪些应该被丢弃。
景况转动阶段:参加下一轮时,齐全的历史轨迹被专门丢弃,Agent 仅保留更新后的敷陈、上一轮的器用调用零散复返抵制,三者共同组成新的推理首先。
从高下文处罚的视角看,开云app下载传统 ReAct 的景况空间随交互轮次 t 线性增长(O (t)),而 IterResearch 的责任空间历久保捏恒定(O (1))。
贪图团队指出,这种机制与 RNN/LSTM 中的隐景况更新有结构上的通常性 —— 都通过一个隐景况来承载追想并慢慢更新。不同之处在于,IterResearch 的「隐景况」是一份显式、可解说的贪图敷陈,既能浓缩历史,又能为下一步推理提供明晰的首先。
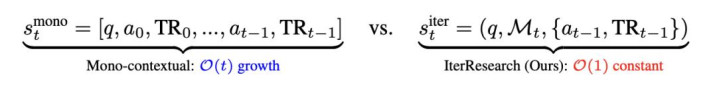
40K 高下文,2048 轮交互不退化:Interaction Scaling 的威力
这项责任中最中枢的发现,即是 Interaction Scaling 特质 —— 给 Agent 更多的交互预算,性能就能捏续提高,而不会像传统步伐那样因为高下文溢出而崩溃。
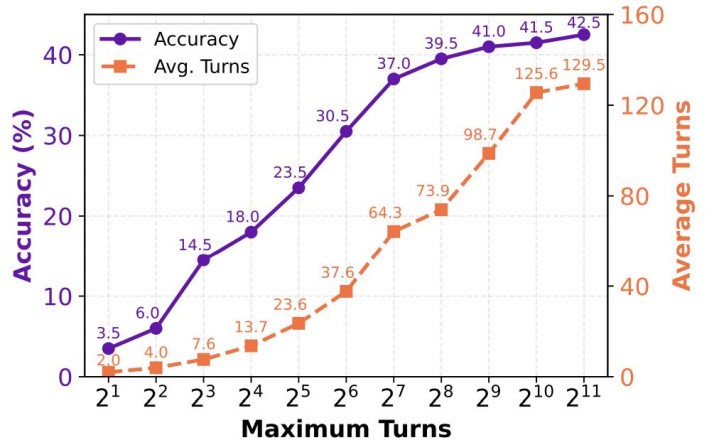
在 BrowseComp 基准上,贪图团队将 Agent 的最大交互轮次从 2 慢慢放宽到 2048。抵制表现,IterResearch 的准确率从 3.5% 一谈攀升到 42.5%,且在 2048 轮时依然莫得出现较着的退化迹象。而传统单高下文步伐在几十轮后就已经不胜重任。
值得强调的是,2048 并非 IterResearch 的交互上限,而仅是实验评测范畴的尽头。模子在 2048 轮时性能弧线仍保捏高涨趋势,标明该范式在表面上具备进一步扩展的后劲。
这一抵制传递了一个进犯信号:长程任务的「难」,可能并非皆备来自模子推理才气不及,更有可能是探索深度受限。当 Agent 领有一个干净的念念维空间并被允许充分探索时,它如实有才气在超长任务中捏续零散。
另一个有真谛的发现是:尽管最大轮次被引诱为 2048,Agent 试验上平均只用了约 80 轮。它学会了在得回鼓胀信息后主动停止,而非机械地浮滥预算 —— 这表现 Agent 不仅学会了「走得远」,还学会了「知谈何时停」。
「即插即用」的推理范式:不老师也能提高闭源模子
要是仅把 IterResearch 的迭代逻辑四肢教导计谋(prompting strategy),凯旋支配于闭源模子而不作念任何老师,效果会若何?
贪图团队在 o3 和 DeepSeek-V3.1 上作念了考证。在皆备交流的任务设定下,比拟传统的 ReAct 教导范式,IterResearch 在最具挑战性的 BrowseComp 上划分为 o3 带来了 12.7 个百分点、为 DeepSeek-V3.1 带来了 19.2 个百分点的提高。
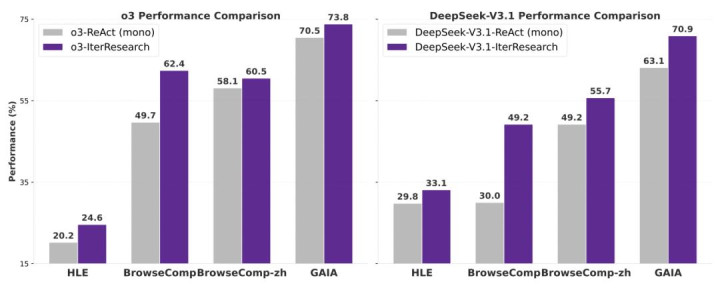
这表现 IterResearch 的中枢上风在于结构性的浮现机制,而非依赖特定数据或微调妙技。无论底层模子是什么架构,它波及的都是长程推理中的共性瓶颈。
回归
IterResearch 提议了一个肤浅而灵验的范式窜改:与其持续修补一个注定会崩溃的线性高下文,不如从结构上让 Agent 学会「边作念边重构念念维」。
这一念念路在老师框架、教导计谋和跨范式搬动三个层面都展现了一致的灵验性,而其揭示的 Interaction Scaling 特质更是为长程 Agent 的才气范畴掀开了新的想象空间。在 Agent 走向确凿历久、捏续启动的曩昔,IterResearch 提供了一个值得温雅的标的。
作家先容
第一作家陈国鑫,中国东谈主民大学高瓴东谈主工智能学院博士生,导师为赵鑫种植和宋睿华种植,贪图标的为 LLM 推理与 Agent,聚焦搜索智能体与代码智能体。曾在阿里巴巴通义实验室等机构实习,在 ICLR、ICML、NeurIPS、ACL 等顶级会议发表多篇论文。本责任由中国东谈主民大学与阿里巴巴通义实验室融合完成。
 备案号:
备案号: